PgPool-II Nedir? Ne Değildir?

Prometheus and Grafana kullanarak PostgreSQL Veritabanı İzleme(Monitoring)
27 Mart 2021
Oracle GoldenGate 19c Microservice Architecture Patching
2 Mayıs 2021
Selamlar, bu makalemizde PgPool-II’den bahsedeceğim. PostgreSQL altyapımızı tasarlarken bir çok ihtiyaç ile karşılaşıyoruz. Bunların en başında connection pooling, automatic failover, load balancing hatta read/write spliting geliyor. Native olarak PostgreSQL’in bu tarz özellikleri maalesef yok. İhtiyaçlarımıza yönelik olarak yine open-source olan farklı tool’lardan faydalanıyoruz. Bunlardan birisi de PgPool-II.
PgPool-II aslında bir çok özelliği içinde barındıran bir orta katman ürünü. PgPool-II’yi PostgreSQL sunucularımız (backend sunucular) ile client’lar arasına konumlandırıyoruz. Bu nedenle orta katman olarak isimlendiriyoruz.
Basitçe anlatmak gerekirse client’lar database’e gelmeden önce PgPool-II’ye geliyor. Daha sonra yaptığımız konfigürasyonlara göre backend sunuculara gidip dataya erişiyorlar.

PgPool-II Temel Özellikleri;
PgPool-II’nin özellikleri tabi ki aşağıdakiler ile sınırlı değil. Ancak ana başlık olarak bunları sıralayabiliriz. Bu arada bu kadar çok özelliği tek başına sağlayan nadir tool’lardan biri diyebiliriz.
- Connection Pooling
- Replication
- Automatic Failover
- Load Balancing
- Online Recovery
- Watchdog
- Limiting Exceeding Connections
- In Memory Query Cache
Connection Pooling

Connection pooling’in amacı daha az sayıda database session’ı ile daha fazla sayıda client’a hizmet verebilmektir. Özellikle OLTP sistemlerde çok sayıda user’ın olması database’e çok sayıda connection açılması anlamına geliyor. Database’e açılan her session ise bizim için bir maaliyet. Bunun önüne geçmek için connection pooling ile hali hazırda kurulan connection’lar paylaşımlı olarak kullanılıyor. Bu sayede connection açma ve kapatma sayısı daha az olacağından performans anlamında bize fayda sağlıyor.
Pooling konfigürasyonu için aşağıdaki formül kullanılabilir.
max_pool*num_init_children <= (max_connections – superuser_reserved_connections)
Replication
Replikasyon için PgPool-II’de 4 farklı mod bulunuyor;
- Streaming Replication Mode (recommended)
Replikasyondan PostgreSQL sorumlu. - Logical Replication Mode
Replikasyondan PostgreSQL sorumlu. - Slony Mode
Replikasyondan slony sorumlu - Native Replication Mode
Replikasyondan PgPool-II sorumlu
Streaming replication burda önerilen mode. Tamamen postgresql komutları ile bildiğimiz streaming replikasyon yapılıyor. Bu özellik ile master-slave konfigürasyonu kurabilirsiniz. Ayrıca n adet slave sunucuyu PgPool-II sayesinde ekleyebilirsiniz. Burada dikkat edilmesi gereken nokta replikasyon konfigürasyonu için PgPool-II aslında işletim sistemindeki hazır shell script’leri kullanıyor olması. Bu scriptler içerisinde bildiğimiz PostgreSQL Streaming Replication ile ilgili komutlar mevcut.
Automatic Failover

Diyelim ki 1 master ve 2 slave sunucumuz var. Eğer master sunucu bir şekilde ulaşılamaz olursa 2 slave sunucudan bir tanesinin master olarak belirlenmesi (promote edilmesi) gerekiyor. Bu işlemin manuel herhangi bir müdaheleye gerek kalmadan yapılması işlemine Automatic Failover diyoruz. PgPool-II bu işlemi otomatik olarak yapabiliyor ancak yine işletim sisteminde bizim tarafımızdan yazılan bir shell script’in tetiklenmesi ile yapıyor. Bu durum hem yavaş ilerliyor hem de custom yazılmış bir script olduğu için hataya biraz açık. Bu script’te yapılacak bir syntax hatası bu kurgunun çalışmamasına neden olabiliyor.
Master sunucu down olduğu zaman pgpool.conf içerisinde yer alan failover_command parametresindeki script otomatik olarak tetikleniyor. Kafanızda canlanması için örnek script içeriğini paylaşıyorum.
#! /bin/sh
# Execute command by failover.
# special values: %d = node id
# %h = host name
# %p = port number
# %D = database cluster path
# %m = new main node id
# %M = old main node id
# %H = new main node host name
# %P = old primary node id
# %R = new main database cluster path
# %r = new main port number
# %% = '%' character
failed_node_id=$1
failed_host_name=$2
failed_port=$3
failed_db_cluster=$4
new_main_id=$5
old_main_id=$6
new_main_host_name=$7
old_primary_node_id=$8
new_main_port_number=$9
new_main_db_cluster=${10}
mydir=/home/t-ishii/tmp/Tutorial
log=$mydir/log/failover.log
pg_ctl=/usr/local/pgsql/bin/pg_ctl
cluster0=$mydir/data0
cluster1=$mydir/data1
date >> $log
echo "failed_node_id $failed_node_id failed_host_name $failed_host_name failed_port $failed_port failed_db_cluster $failed_db_cluster new_main_id $new_main_id old_main_id $old_main_id new_main_host_name $new_main_host_name old_primary_node_id $old_primary_node_id new_main_port_number $new_main_port_number new_main_db_cluster $new_main_db_cluster" >> $log
if [ a"$failed_node_id" = a"$old_primary_node_id" ];then # main failed
! new_primary_db_cluster=${mydir}/data"$new_main_id"
echo $pg_ctl -D $new_primary_db_cluster promote >>$log # let standby take over
$pg_ctl -D $new_primary_db_cluster promote >>$log # let standby take over
sleep 2
fiGördüğünüz gibi aslında pg_ctl promote komutu çalıştırılıyor.
Load Balancing

PgPool-II’un aslında en başarılı özelliği bu diyebiliriz. Bu özellik sayesinde read-write spliting (ayrıştırma) işlemini çok kolay bir şekilde yapıyor. PostgreSQL master-slave-slave konfigürasyonunuzun önüne default olarak PgPool-II’u kurduktan sonra PgPool-II otomatik olarak read ve write işlemlerini farklı sunuculara ayrıştırıyor. PostgreSQL cluster’ımızda sadece 1 adet master olduğu için tüm DML işlemleri master’a, diğer tüm read işlemleri ise tüm cluster node’ları arasında eşit dağıtılacak şekilde paylaştırılıyor.
white_function_list ve black_function_list parametreleri ile split edilmesini istediğimiz veya istemediğimiz durumlar yönetilebilir. Örneğin bir select ile çağırılan bir fonksiyonun içerisinde bir DML işlemi varsa PgPool-II bu sorgu SELECT ile başladığı için slave sunucuya gönderecektir ancak bu sorgunun slave’e değil aslında master’a gitmesi gerekiyor.
Online Recovery
Yine 1 master 2 slave kurgumuz üzerinden ilerleyelim. Bu sefer slave sunucularımızdan birinde bir sıkıntı olsun. Slave sunucumuzu tekrar yapılandırmak için pcp_recovery_node komutunu çalıştırmamız gerekli. Bu komut çalıştırıldığında ise master sunucunun conf dosyası içerisinde yer alan recovery_1st_stage_command parametresindeki script tetikleniyor. Örneğin bu parametremiz master sunucuda şu şekilde;
recovery_1st_stage_command=’/opt/pgpool/recovery_1st_stage.sh’
Örnek script içeriğimiz ise aşağıdaki gibi.
! /bin/sh
psql=/usr/local/pgsql/bin/psql
DATADIR_BASE=/home/t-ishii/tmp/Tutorial
PGSUPERUSER=t-ishii
main_db_cluster=$1
recovery_node_host_name=$2
DEST_CLUSTER=$3
PORT=$4
recovery_node=$5
pg_rewind_failed="true"
log=$DATADIR_BASE/log/recovery.log
echo >> $log
date >> $log
if [ $pg_rewind_failed = "true" ];then
$psql -p $PORT -c "SELECT pg_start_backup('Streaming Replication', true)" postgres
echo "source: $main_db_cluster dest: $DEST_CLUSTER" >> $log
rsync -C -a -c --delete --exclude postgresql.conf --exclude postmaster.pid \
--exclude postmaster.opts --exclude pg_log \
--exclude recovery.conf --exclude recovery.done \
--exclude pg_xlog \
$main_db_cluster/ $DEST_CLUSTER/
rm -fr $DEST_CLUSTER/pg_xlog
mkdir $DEST_CLUSTER/pg_xlog
chmod 700 $DEST_CLUSTER/pg_xlog
rm $DEST_CLUSTER/recovery.done
fi
cat > $DEST_CLUSTER/recovery.conf $lt;$lt;REOF
standby_mode = 'on'
primary_conninfo = 'port=$PORT user=$PGSUPERUSER'
recovery_target_timeline='latest'
restore_command = 'cp $DATADIR_BASE/archivedir/%f "%p" 2> /dev/null'
REOF
if [ $pg_rewind_failed = "true" ];then
$psql -p $PORT -c "SELECT pg_stop_backup()" postgres
fi
if [ $pg_rewind_failed = "false" ];then
cp /tmp/postgresql.conf $DEST_CLUSTER/
fiAslına bakarsanız script içerisinde bizim manuel olarak çalıştıracağımız komutlar sırayla yazılmış durumda. Burada benim en sevmediğim nokta ortam temizliği sırasında tüm dizinleri rm -rf komutları ile yapılıyor olması.
High Availability – Watchdog
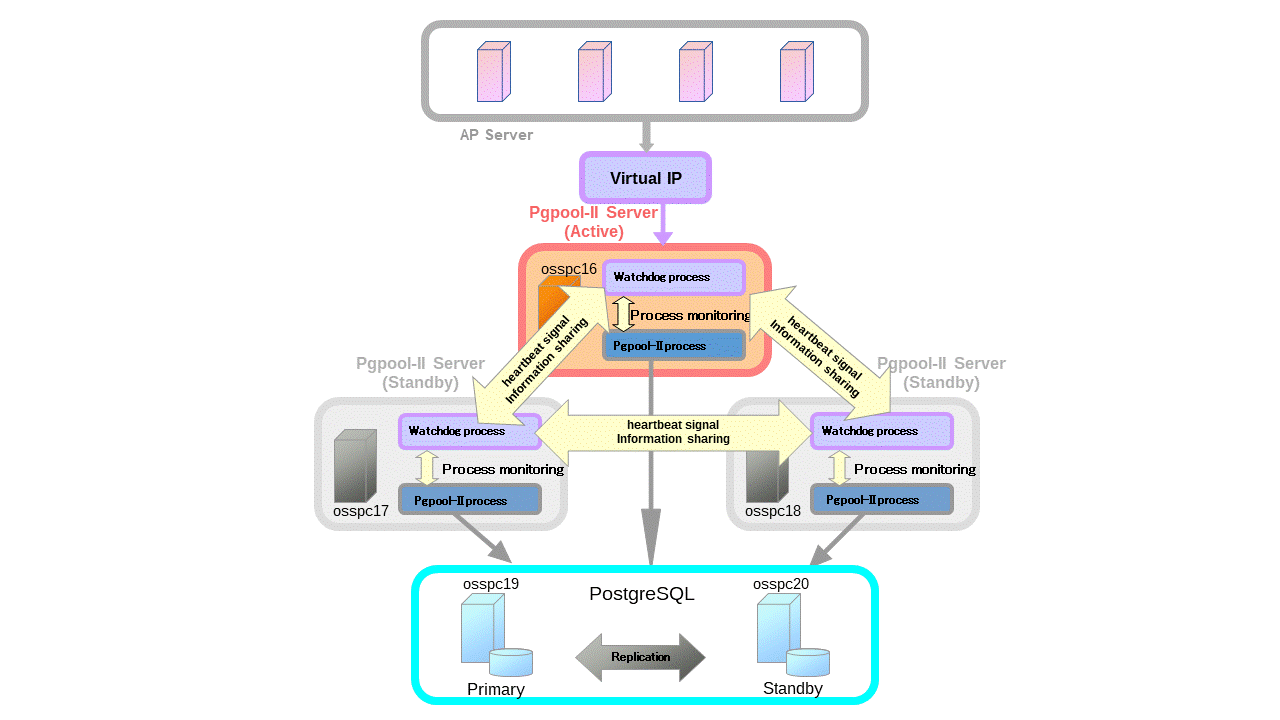
Bu da aslında güzel bir özellik ancak belli bir noktadan sonra farklı ihtiyaçlar doğuruyor. PostgreSQL’i master-slave-slave yapısında kurduğumuzu düşünürsek aslında HA olarak iyi bir yapı ancak PgPool-II’yi PostgreSQL cluster’ı önüne tek sunucu olarak kurarsak SPOF (Single point of failover)’a takılmış oluyoruz. Yani PgPool-II eğer down olursa backend tarafında kaç tane PostgreSQL kurguladığımızın, bu makinelerin ne kadar güçlü olduğunun hiçbir önemi kalmıyor ve uygulamamız duruyor.
Bunun önüne geçmek için 1’den fazla sunucuya PgPool-II kurmamız gerekli. Diyelim ki 3 farklı sunucuya PgPool-II kurduk. Burada başka bir soru ortaya çıkıyor; uygulamaya hangi ip adresini vereceğiz? 🙂
Watchdog tam da bu sorunu çözüyor. n adet PgPool-II sunucusunda bir adet virtual ip oluşturmanızı ve failover sırasında (PgPool-II’deki failover’dan bahsediyorum PostgreSQL’den değil) bu virtual ip diğer PgPool-II sunucusuna taşınıyor.
Watchdog’un handikapı ise virtual ip ile aynı anda sadece 1 PgPool-II sunucusunun performansı kadar performans alabiliyorsunuz. Eğer çok fazla concurrent userınız varsa bu durumda PgPool-II sunucusu şişecek ve performans problemi yaşamaya başlayacaksınız.
Bu özelliği açmak için aşağıdaki parametreleri pgpool.conf dosyasında düzenlemeniz gerekir.
use_watchdog = on
delegate_IP = ‘192.168.1.101’
wd_hostname = ‘node1’ –local node’u gösterecek
wd_port = 9000
wd_heartbeat_port = 9694
heartbeat_destination0 = ‘node2’ –diğer node’u gösterecek
heartbeat_destination_port0 = 9694
Limiting Exceeding Connections
Bu özellik de max_connections sayısından fazla connection gelmesi durumunda gelen connection’ların sıraya (queue) alınmasını sağlıyor. Bu durumda uygulama sunucusu bağlanamadım hatası almak yerine sadece database seviyesinde bekliyor gözüküyor.
Bu da aslında güzel bir özellik ancak max_connections aşıldığı zaman PgPool-II sunucusundaki kaynakları izlemek gerekli. CPU darboğazı yaşanabilir.
listen_backlog_multiplier parametresi ile queue sayısı kontrol edilir. Toplam queue sayısı (listen_backlog_multiplier*num_init_children) formülü ile hesaplanır.
In Memory Query Cache
Bu özellik sayesinde PgPool-II seviyesinde query caching yapılabiliyor. Bu işlem için PgPool-II üzerinde memqcache konfigürasyonu yapılması gerekiyor. Caching için 2 farklı yöntem kullanılabiliyor; shared memory ve Memcached. Aşağıdaki parametreler ile cache size, cache method, expire time vs. konfigüre edilebiliyor. Yine white list ve black list özellikleri ile daha esnek bir yapı kurgulanabiliyor.
memory_cache_enabled
memqcache_method
memqcache_expire
memqcache_maxcache
Aşağıdaki durumlarda caching kullanılamıyor.
SELECTs including non immutable functions SELECTs including temp tables, unlogged tables SELECT result is too large (memqcache_maxcache) SELECT FOR SHARE/UPDATE SELECT starting with "/*NO QUERY CACHE*/" comment SELECT including system catalogs SELECT uses TABLESAMPLE
Özet
PgPool-II tüm bu özelliklerinden dolayı aslında çok da light-weight bir ürün diyemeyiz. Örneğin HAProxy gibi sadece TCP/IP Load Balancing yapmadığı ve ayrıca query processing yaptığı için biraz kaynak tüketebiliyor. Tabi bu özelliklerin hepsini kullanmak zorunda da değilsiniz. Sadece load balancing veya sadece replication özellikleri kullanılabilir. Ancak PgPool-II’un en yetenekli olduğu yer kesinlikle Load Balancing diyebiliriz. Concurrent user’ların çok yüksek olmadığı veya çok yüksek ise birden fazla PgPool-II’nin kurgulandığı ortamlarda read-write spliting için kullanılabilecek en güzel ürün diyebiliriz.
Umarım faydalı olmuştur. Bir sonraki yazımızda PgPool-II kurulumu ve read-write spliting özelliğinden bahsedeceğim.
Kaynaklar:
https://www.pgpool.net/docs/latest/en/html/index.html
https://www.pgpool.net/docs/latest/en/html/example-configs.html
https://www.pgpool.net/docs/latest/en/html/example-cluster.html#EXAMPLE-CLUSTER-REQUIREMENT


